Related Topics:
Worlds Superpowers 2025-

AI Technology Applied to Servers
AI servers are specialized systems using powerful GPUs for the intensive, parallel processing of AI models. Enterprises are investing billions of dollars in cloud. Related: Dell, HPE, and Others Unveil AI Innovations at GTC 2026 IDC reports the global server market reached a record $444 billion in 2025. With AI infrastructure remaining a strategic priority, IDC projects AI infrastructure spending will reach $487 billion in 2026 and surpass $1 trillion by. As AI accelerates from research labs to everyday operations, its footprint now spans cloud-scale training, on-premises systems, and billions of connected devices. Yet most AI services still assume a stable network path to distant data centers. These servers feature high-speed interconnects and large, fast. AI, or artificial intelligence, is changing the way organizations and businesses handle data by incorporating automation of complex calculations, introducing new advanced applications, and fulfilling computational demands like never before.
[PDF Version]
-

AI computing server price
Standard 3–5 year plans typically range from $15,000 to $40,000 per server, covering firmware, diagnostics, and parts replacement. Vendors like Supermicro offer flexible, OpEx-friendly options to help manage these expenses. AI servers, such as the HPE XD685 and Dell XE9680, equipped with eight NVIDIA H100 or H200 GPUs, consume over 7 kW per node, surpassing the 200–400 W baseline of traditional servers. This seismic shift in power demand transforms the economics of AI infrastructure. The cost of an AI server data. The AI data center market is valued at USD 344. 52 billion by 2032, growing at a CAGR of 27. Growth is driven by rising adoption of generative AI, machine learning, and large language models across industries, as well. AI implementation costs range from $5,000 for pilots to $500K+ for enterprise systems. Every layer of the stack, including GPU modules, memory, networking, power, and cooling, has repriced sharply heading into 2026.
[PDF Version]
-

Direct Sales of AI Server SFP
The server market has grown steeply during Q2 2024 due to the strong demand for AI servers, increasing 35% YoY. Dell, Supermicro, HPE are the big 3. But ODM direct sales dominate as Microsoft, Amazon, Google and Meta continue to custom order their own servers. Counterpoint Research has published. AI Server Market Size, Share and Trends Analysis Report By Processor Type (GPUs, CPUs, FPGAs, ASICs), By Form Factor (Rack-Mounted Servers, Blade Servers, Tower Servers, Microservers), By Deployment Model (On-Premises, Cloud, Hybrid), Memory Capacity (Up to 512GB, Up to 1TB, Up to 2TB, Over 2TB). The AI server market is projected to reach USD 837. 83 billion by 2030 from USD 142. The North America AI server market accounted. The global AI server market size was estimated at USD 131. Cloud computing and hyperscale data center expansion are driving the market growth. 2% revenue. Dell, HPE, Lenovo, and Supermicro are riding record AI server demand, but winning enterprise customers requires more than just Nvidia chips.
[PDF Version]
-

What is an AI computing server
AI servers are high-performance computing systems designed to process complex artificial intelligence workloads, including large-scale model training and real-time inference. They provide the hardware environment —. AI, or artificial intelligence, is changing the way organizations and businesses handle data by incorporating automation of complex calculations, introducing new advanced applications, and fulfilling computational demands like never before. Machine learning models train on patterns. An AI server's architecture is all about.
-

Does Laos have AI servers now
Laos is making a significant leap in digital development with the launch of its first large-scale Artificial Intelligence (AI) system. Investment in the region's data centers reached USD 10. 23 billion in 2023, with projections expecting this figure to climb. Laos accounts for null AI patents (2024), null of AI Investments (2025), and 7 of AI Publications (2024). Vientiane is emerging as the focal point for tech and AI activities, supported by government initiatives and international partnerships. However, AI development is still in its. KPL Vientiane, May 30, 2025, the National Data Center, under the Ministry of Technology and Communications, has signed a memorandum of understanding (MoU) with Silicon Tech Park (Lao) Sole Co. la/freefreenews/freecontent_034_Laos_China_y26.
-

AI Server Delineation
AI servers are high-performance computing systems designed to process complex artificial intelligence workloads, including large-scale model training and real-time inference. This is where AI server clusters stand out, crafted for. Building and setting up your very own high-performance local AI server offers a fantastic solution to this. Indeed, the AI server market was valued at $38. 3 billion in 2023 and is estimated by Global Market. to design-center-comments@juniper. In this document, we explore the network infrastructure requirements of AI.
-

What to do if there is a problem with the AI Link server
This guide provides a structured approach to troubleshooting network link failures in AI data centers, specifically targeting issues where the link cannot up. "Is It Down Right Now" monitors the status of your favorite web sites and checks whether they are down or not. Just enter the url and a fresh site status test will be performed on the domain name in real time using our online website. Unable to access your agents Public access is disabled in the AI Service. Please open and configure a private endpoint connection. Learn more I've also tried to setup the Azure AIHub where the project is deployed by enabling the managed virtual network option and creating a private endpoint for the. Find out if a service is down in seconds. com" or "Gemini". Our system instantly pings the service from multiple global locations to verify its status. Get a clear 'Up' or 'Down' status in real-time. ” or “Hmm, something isn't right.
[PDF Version]
-
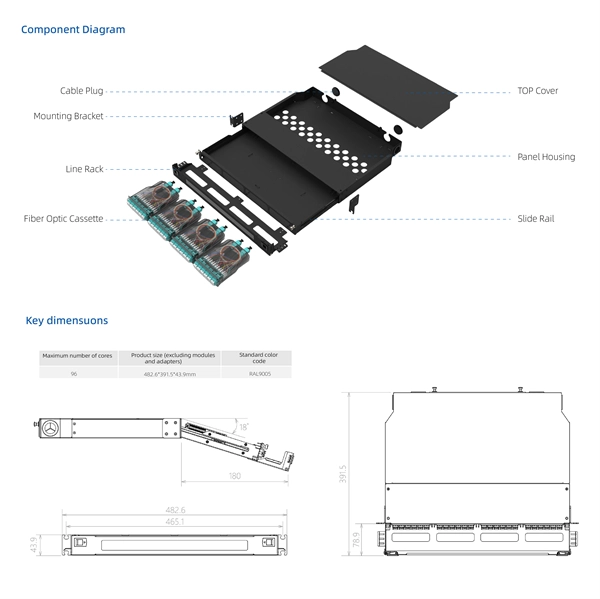
Two fiber optic cables are connected to the back of the switch
Choose an SFP module based on the fiber optic cabling that will be connected to the network switches. In addition, fiber cables can transmit data over several kilometers without signal degradation, making them ideal for connecting switches in large campus networks and between different buildings. As they do not emit electromagnetic signals, they're difficult to tap and secure against eavesdropping. I need to connect 4 Floor Building with 4 Cisco 2960 - 48 ports switch each other and it needs to be through a fiber. Can two switches with optical ports be directly connected by optical fiber? Yes, the main line of the optical fiber LAN is a direct. SFP transceiver modules are specific to the type of fiber being connected (either single mode or multimode). Always. In this video, we'll delve into the world of fiber optics, exploring the reasons behind their necessity, introducing Fiber Switches and Fiber PoE Switches, guiding you through the selection of the right fiber optic cables, and demonstrating the physical connection process.
[PDF Version]
-

Jamaica AI Server
A new locally built artificial intelligence platform, Maestro AI, is now entering its final phase of testing, with its creators signalling ambitions not only for national impact, but also regional expansion and a future public listing to support growth. Caption: Technologies designed abroad are shaping national economies, information ecosystems and capacity to respond to climate and development challenges. StarApple AI Jamaica is a. Jamaica has made significant strides toward preparing for the age of artificial intelligence. The UNESCO-led Readiness Assessment highlighted that Jamaica already has a strong digital foundation: high internet penetration and mobile adoption, a Data Protection Act (2020) that grants rights such as. While global tech hubs dominate headlines, a unique opportunity emerges for Jamaica to position itself as the region's AI innovation center. With strategic advantages in location, culture, and emerging infrastructure, Jamaica can transform from an observer to a leader in the artificial intelligence. Jamaica is emerging as a dynamic player in the Caribbean tech ecosystem, with Kingston leading the way in AI-related activities.
[PDF Version]
-

South Korean AI Artificial Intelligence Server
SK Group has announced plans to build a dedicated artificial intelligence (AI) data center for Amazon Web Services (AWS), the world's leading cloud provider, in the city of Ulsan. The facility will be the largest AI data center in South Korea, equipped with 60,000 graphics. South Korea is rapidly establishing itself as a global force in AI innovation, propelled by a unique blend of industrial strength, technological ambition, and cultural adaptability. Massive AI infrastructure – Korean conglomerate SK Group and U. AI (Artificial Intelligence) is the 4th most popular industry and market group. The market is projected to grow to USD 7. 87 billion by 2032, exhibiting a CAGR of 33. As of 2025, South Korea is emerging as a dynamic force in the. The Korean government, through the Ministry of Science and ICT, is investing in sovereign AI infrastructure with over 50,000 of the latest NVIDIA GPUs to be deployed across the National AI Computing Center and Korean cloud service and IT providers NHN Cloud, Kakao Corp.
[PDF Version]
-

AI for checking server faults
In 2025, leveraging AI-driven monitoring is essential for maintaining server reliability and efficiency. Automated Issue Resolution: AI-powered tools fix. Traditional server monitoring tools rely on static thresholds and rules, which can miss subtle anomalies or fail to predict issues before they escalate. How Does AI-Based Server Failure Prediction Work? AI-based server failure prediction relies on analyzing large amounts of data collected continuously through. In this guide, we'll dissect the 15 best AI network monitoring tools reshaping enterprise IT in 2025, backed by hands-on insights and comparative analysis. Machine-learning algorithms create adaptive baselines.
-

AI Server Network Architecture Diagram
Prompt with text or voice and our AI generates an editable network diagram in seconds. Visualize servers, routers, devices, and connections to design clear IT infrastructure and networks. What is a network diagram? Cloudairy's AI network diagram generator. AI is a technology that machines use to imitate intelligent human behavior. Machines can use AI to do the following tasks: Analyze data to create images and videos. Verbally interact in natural ways. net's AI Network Diagram Generator converts infrastructure ideas into. Broadcom's Ethernet Adapters (also referred to as Ethernet NICs) along with Arista Networks' switches (based on Broadcom's DNX and XGS family of ASICs) leverage RDMA (Remote Direct Memory Access) to eliminate any connectivity bottlenecks and facilitate a high-throughput, low-latency transport. Common ICT and mechanical devices share a 5DR power distribution architecture.
[PDF Version]
-

Alibaba AI Server Development and Investment
plans to invest 380 billion yuan ($56 billion) in AI data centers over the next three years, a strategic pivot that comes as CEO Eddie Wu Yongming confirms the company's servers are almost completely utilized, signaling a massive buildout to compete in. Alibaba Group Holding Ltd. The investment follows a quarter where profits fell sharply, showing a strategic choice to prioritize AI growth over short-term earnings. The investment, which exceeds Alibaba's total AI and cloud spending over. Alibaba is accelerating investment in cloud computing and artificial intelligence as competition intensifies across China's technology sector. Speaking during the company's Fiscal Year 2025 Q3 earnings call, CEO Eddie Wu noted that the company was planning to scale up its investments as part. Alibaba has announced a strategic plan to invest at least 380 billion yuan ($52.
[PDF Version]